En el presente artículo vamos a realizar un viaje al pasado, en concreto al sábado 10 de noviembre de 2018. Dicho día, mi compañero Gonzalo González a.k.a Gonx0 y yo (Iván Portillo – @IvanPorMor) impartimos un taller sobre ciberinteligencia en el congreso sobre ciberseguridad HoneyCON bajo el título “Monta la NSA en tu casa: Inteligencia aplicada al mundo cyber”.
El taller comenzó con una introducción sobre qué es la Inteligencia y como está relacionado con la ciberseguridad. Durante el mismo indicamos la problemática existente en la actualidad a la hora de obtener información de múltiples fuentes y herramientas. En la recta final presentamos una posible solución a lo mencionado, por medio de una metodología automatizada que permite la recolección de información y el almacenamiento de estos en una base de datos de grafos donde el analista puede consultar las relaciones existentes entre los mismos. De esta forma seria posible generar la inteligencia accionable a partir de unos pocos datos de origen.
[su_spoiler title=»CONTENIDO DEL ARTÍCULO» open=»yes» style=»fancy» icon=»caret-square» anchor=»indice» class=»my-custom-spoiler»]
- Desarrollo del taller
- Introducción a la Inteligencia
- Conceptos y fundamentos de la Ciberinteligencia
- El problema a resolver
- Recolección de información
- Visualización del video del taller
- Visualización de la presentación del taller
- Conclusión
[/su_spoiler]
Desarrollo del taller
Mi compañero Gonzalo González a.k.a Gonx0 y yo impartimos hace 2 años un taller sobre Ciberinteligencia en el congreso HoneyCON. El objetivo del taller fue presentar conceptos básicos de Inteligencia a un público meramente técnico, con la idea de que vieran las sinergias existentes entre esta y el mundo de la ciberseguridad. El propio taller estuvo centrado en la fase de obtención del famoso Ciclo de Inteligencia, donde planteamos un caso práctico a investigar de manera manual. Por último, mostramos una posible solución a las limitaciones presentes en los procesos manuales a través de una automatización para la recopilación de grandes volúmenes de datos.
El propio taller lo estructuramos en las siguientes secciones:
- Introducción a la Inteligencia
- Conceptos y fundamentos de la Ciberinteligencia
- El problema a resolver
- Recolección de información

Introducción a la Inteligencia
El taller comenzó con unos conceptos introductorios sobre las fuentes que pueden ser utilizadas para generar inteligencia. En función del medio desde donde sean obtenidos los datos, serán conocidos de una forma u otra. Dichas fuentes son conocidas también como disciplinas de inteligencia, siendo las siguientes:
- OSINT. Inteligencia de Fuentes Abiertas
- SOCMINT. Inteligencia de Medios Sociales
- HUMINT. Inteligencia de Fuentes Humanas
- SIGINT. Inteligencia de Señales
- GEOINT. Inteligencia Geospacial
- Inteligencia generada a partir de fuentes de la Deep Web
Todo este proceso de generación de inteligencia utiliza lo que se conoce como el Ciclo de Inteligencia. Dicho ciclo sigue de manera secuencial una serie de fases donde los resultados de cada una de estas serán el punto de partida de la siguiente. En el taller mencionamos los modelos utilizados actualmente por la CIA y el CNI. Si deseáis conocer más al respecto, podéis consultar el artículo «Introducción a la Inteligencia«.
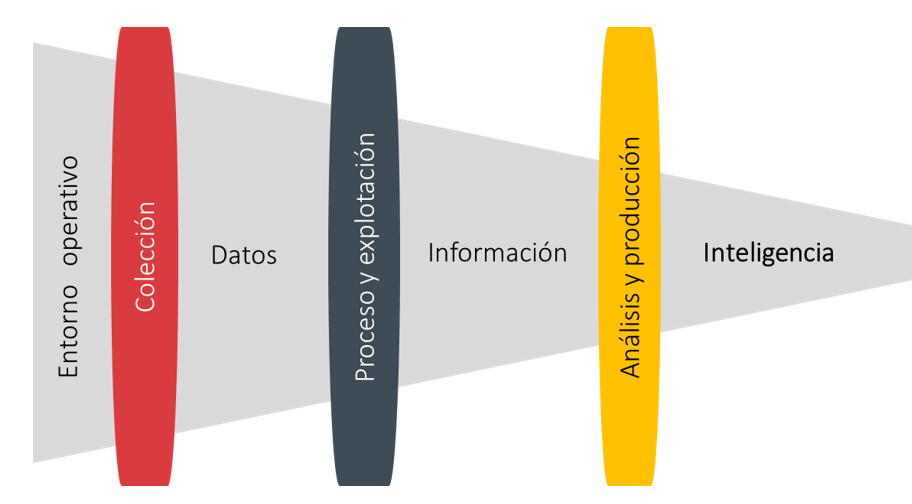
La propia Inteligencia parte en muchas ocasiones de una unidad mínima de valor proveniente del entorno operativo utilizado para ello, el cual, se conoce como dato. Ahora, si comenzamos a tratar y procesar el dato obtenido estaremos transformándolo a esa información todavía sin evaluar pero útil para trabajar. En este momento deberemos aplicar técnicas de análisis a dicha información para poder generar el famoso producto de Inteligencia. No debemos olvidar nunca que dicho producto tiene que servir para que esa persona que ha solicitado ayuda pueda tomar las decisiones pertinentes.
Finalizamos esta sección hablando sobre la diferencia existente entre riesgo y amenaza, conceptos relacionados pero distintos.

Conceptos y fundamentos de la Ciberinteligencia
En esta sección mostramos él porque es necesaria la ciberinteligencia a nivel general, junto a una serie de conceptos básicos sobre esta disciplina de inteligencia.
Cada día que avanza, la tecnología va evolucionado de manera inimaginable. Los criminales sacan provecho de esta situación y se adaptan a las nuevas tecnologías, donde esta les permite en algunas ocasiones añadir más capas de anonimato para ocultar sus huellas e identidad.
Las amenazas tienen un nexo de unión con algunas tecnologías en particular, ya que la gran mayoría de ataques aprovechan ciertas vulnerabilidades presentes en softwares o sistemas. Esta evolución afecta a las amenazas, al existir un vínculo entre ambas, lo que genera que las amenazas sean cada vez más sofisticadas, superando las defensas de seguridad y los enfoques operativos más tradicionales. Estas defensas mencionadas son cada vez menos efectivas.
La concienciación en seguridad es de vital importancia para proteger mejor la organización, siendo el empleado el eslabón más débil. Es de vital importancia formar al empleado en nociones básicas de seguridad. Entre las amenazas más actuales destaca la Ingeniería Social, utilizando diferentes tipos de técnicas de engaño con el objetivo de efectuar ataques dirigidos hacia empleados concretos.

El problema a resolver
En esta sección hablamos nuevamente sobre el Ciclo de Inteligencia, pero esta vez adaptado y centrado en una monitorización de amenazas. Las propias fases que mencionamos en el taller son las siguientes:
- Recoger. Fase encargada de obtener los datos de fuentes externas e internas
- Analizar. Esta fase se centra en la evaluación de los datos recogidos en la fase anterior con el fin de identificar los TTPs y la intencionalidad del actor, entre otra información de valor.
- Producir. Fase encargada en la elaboración del propio producto de inteligencia
- Integrar. Fase centrada en la entrega del producto de Inteligencia o la refinación de los requisitos.
Para acabar esta sección hablamos sobre los cuatro niveles de Inteligencia, que en función del interlocutor que consuma el producto de Inteligencia se utilizará uno u otro tipo. Dichos niveles derivan del mundo militar siendo estos la Inteligencia Estratégica, la Táctica u Operacional, donde debido a la gran auge de la tecnología en los últimos años surgió un nuevo nivel denominado Inteligencia Técnica. Haciendo un resumen sobre dichos niveles tenemos lo siguiente:
- Estratégica. Producto que contiene información de alto nivel, dirigida hacia altos cargos de una organización, agencia o estado, donde este debe contener un breve resumen ejecutivo de tres párrafos con lo más importante del suceso para que puedan tomar decisiones
- Táctica. Contiene información sobre las tácticas, técnicas y procedimientos utilizados por los actores para determinar quiénes son los adversarios, qué usan, donde y cuando suelen atacar, por qué realizan dichas acciones y como operan
- Operacional. Cuenta en su interior con información sobre ataques específicos que llegan a la organización, junto con las metodologías y procedimientos empleados para contrarrestar la propia amenaza. Además, cuenta en la gran mayoría de los casos de información de las operaciones y actividades en curso. En este nivel es donde actúan los equipos operativos como Blue Team, Red Team y personal de respuesta a incidentes, entre otros
- Técnica. Este tipo de producto de inteligencia suele tratar información a muy bajo nivel sobre los propios indicadores de compromiso asociados a una amenaza, además de como actúa. Este nivel surgió como apoyo al nivel operacional
Después de lo mencionado, presentamos un escenario en el que pusimos rostros a cada uno de estos niveles simulando un ataque a una empresa. Por cada uno de estos elegimos a un perfil en concreto en función de su cargo profesional, creando una historia donde dichos perfiles interactuaban entre ellos con el fin de solventar el problema que tenían entre manos.

Recolección de información
Esta sección estaba dividida en tres partes. La primera de ellas hablaba sobre los recursos que podemos utilizar para comenzar una investigación desde cero. La segunda parte estaba centrada en cómo utilizar las herramientas presentadas anteriormente para investigar un objetivo de manera automatizada. En la última parte hablamos sobre la importancia que tienen las relaciones entre los datos y la necesidad de ir asociándolos entre sí de manera automatizada.
Como comenzar – Recursos iniciales
Antes de comenzar una investigación necesitaremos una serie de recursos, siendo lo primero una máquina virtual adaptada a nuestras necesidades. Por este hecho mencionamos a lo largo del taller tres centradas en exclusiva a investigaciones OSINT: Buscador 2.0 (no disponible en la actualidad), OSINTUX y HURON.
En este punto ya tendríamos una máquina virtual preparada para investigar, ahora serán necesarias las fuentes y herramientas que podemos utilizar.
Como repositorios de datos mostramos algunas de las existentes, donde podemos localizar información asociada a direcciones IP, rangos IP, dominios, certificados, servicios expuestos y un largo etcétera. A continuación os facilitamos los enlaces actualizados a dichos repositorios:
- Scans.io. Repositorio de datos públicos creado por Censys, que recopila información sobre hosts IPv4, sitios web dentro de Alexa Top Million y certificados X.509 que se encuentren activos en Internet. Todo este proceso de recolección lo efectúa mediante escaneos activos con ZMAP
- Rapid7. Repositorio de datos públicos creado por Rapid7, que realiza escaneos a diferentes servicios y protocolos en Internet para obtener información sobre la exposición global a vulnerabilidades comunes
- RIPE. Registro Regional de Internet (RIR) específico para Europa, Oriente Medio y partes de Asia Central, el cual, permite la obtención de rangos IP (IPv4 e IPv6) y Número de Sistema autónomo, entre otra información
Como repositorios donde consultar enlaces de herramientas online enfocadas en OSINT, mostramos los siguientes:
- Ciberpatrulla. Web en constante actualización dedicada exclusivamente a investigaciones OSINT, contando con un repositorio de herramientas categorizadas por grupos, donde cada una de estas engloba enlaces a herramientas relacionadas a su temática
- OSINT Framework. Sitio web enfocado para investigaciones OSINT, alojando diferentes recursos en forma de enlaces a herramientas agrupadas por categorías y subcategorías en formato árbol
- IntelTechniques. En la actualidad ya no está disponible de manera pública

Herramientas online
Las herramientas que presentamos en esta sección del taller fueron las siguientes:
- Localizar empresas / personas
- LibreBOR. Plataforma web para consultar información del BORME
- Localizar dominios y direcciones IP
- Análisis de malware
- VirusTotal. Herramienta para el análisis de malware, pero que permite obtener datos más allá de esto. Con VirusTotal es posible realizar búsquedas sobre un dominio, direcciónIP,Hash o URL
- Hybrid Analysis. Herramienta similar a VirusTotal en cuanto a detección de Malware se refiere.
- Fugas de información
- Pastebin. Herramienta que permite localizar cualquier tipo de información publicada en pastes
- HaveIbeenPwned. Mediante esta herramienta es posible obtener información sobre los emails que estén presentes en cualquier brecha de seguridad dada
- Localizar activos expuestos en Internet
- Localizar nombres y perfiles de usuarios
En resumen, los asistentes ya dispondrían de un gran conocimiento sobre los repositorios y herramientas online donde comenzar una investigación de manera manual.
Investigación del objetivo
La práctica comenzó con una investigación guiada sobre la empresa afectada por la amenaza, donde la idea principal era intentar descubrir toda la información que estuviera expuesta en Internet de manera pública sin la interacción directa con el objetivo. Posteriormente, los asistentes tenían que llegar a la conclusión de que realizar investigaciones manuales sobre una mediana o gran empresa no era viable, sobre todo en la fase de obtención.
Por esto mismo mostramos como crear y/o reutilizar herramientas automatizadas con el fin de que vieran su utilidad, además de las ventajas asociadas en cuanto a una disminución del tiempo dedicado a la recolección de la información se refiere.
Tal como he comentado, dentro de esta sección enseñamos automatizaciones de algunas de las herramientas mostradas anteriormente como pueden ser RIPE, LibreBOR, Shodan, VisrusTotal, Robtex y HaveIbeenPwned.
Herramientas automatizadas
En esta sección presentamos herramientas open-source muy útiles para recolectar información de manera automática.
- Buscar información sobre dominio principal
- Spiderfoot. Herramienta OSINT que permite efectuar varios tipos de investigaciones consultando múltiples fuentes. Disponéis de un análisis más exhaustivo de su versión en nube aquí
- DataSploit. Permite recolectar información de todo tipo a partir de un dominio
- Recon-ng. Permite efectuar una investigación a partir de un dominio, integrando APIs de multitud de fuentes externas
- Buscar amenazas sobre TypoSquatting
- DNSTwist. Herramienta open source creada para analizar variaciones tipográficas y suplantación de dominios
- Localizar correos electrónicos
- TheHarvester. Herramienta que recopila información sobre un dominio tanto de manera pasiva como activa
- Hunter.io. Es posible obtener información relacionada con perfiles de empleados y/o usuarios. En la actualidad solo es posible obtener 10 resultados por cada petición efectuada vía API y web.
- Localizar fugas de información
- Infoga. Herramienta que permite recopilar información de correos electrónicos de diferentes fuentes públicas, verificando si los correos se encuentran presentes en Data Leaks
- Análisis de perfil de Twitter
- Tinfoleak. Herramienta enfocada en Twitter, que permite extraer información y realizar un análisis sobre un perfil de dicha red social.
- Localizar perfiles de usuarios
- OSRFramework. Herramienta modular que permite obtener información referente a perfiles sociales de usuarios
- Localizar información mediante grafos
- Maltego. Herramienta que recopila información mostrando las evidencias mediante grafos. Contiene una serie de módulos de aplicaciones externas (transformadas), además de una sencilla integración con APIs de distintas fuentes de información
Después de ejecutar cada una de las herramientas listadas, los asistentes pudieron descubrir que por cada una de estas fue generándose un fichero resultante. Esto último es un problema, ya que cada uno de dichos ficheros no compartían la misma estructura de datos, además de no generarse ningún tipo de relación entre los datos de manera automática.
La importancia de las relaciones entre los datos
En esta subsección llegamos a la conclusión de que el método usado no era eficiente. Por este hecho, mostramos una forma mucho más eficiente para la integración de diferentes herramientas entre si, generando las propias relaciones entre los datos.
Para este cometido utilizamos las herramientas de RabbitMQ y neo4j. A continuación os explicamos ambas:
- RabbitMQ. Gestor de colas utilizado para comunicar la información obtenida entre las distintas herramientas ejecutadas. Es software libre y compatible con diferentes protocolos de mensajería.
- Entre sus funcionalidades ofrece lo siguiente:
- Alta disponibilidad
- Garantía de entrega de mensajes
- Escalabilidad Distribución de mensajes a múltiples destinatarios
- Priorización de tareas
- Balanceo de carga


- Neo4j. Es una base de datos orientada a grafos. Permite obtener relaciones entre diferentes nodos de manera gráfica y visual. Dispone de dos versiones: una Community totalmente gratuita y otra de pago.
- Entre sus funcionalidades ofrece lo siguiente:
- Soporta transacciones ACID (Atomicidad, Consistencia, Aislamiento y Durabilidad)
- Agilidad para gestionar grandes cantidades de datos
- Flexibilidad y escalabilidad
- Alta disponibilidad
- Balanceo de carga


La importancia de las relaciones entre los datos – Estructura global de la orquestación
En el taller presentamos una prueba de concepto en el que llevo tiempo trabajando y mejorando. Se trata de una herramienta que permite la recolección de información de manera automática enriqueciendo los datos en función de sus relaciones. La presente herramienta dispone de cuatro tipos de búsqueda que a partir de unos datos de entrada concretos es capaz de autodescubrir todos los datos detectados en busca de las relaciones que puedan existir a través de una monitorización de diversas fuentes. Dichos datos de entrada pueden ser listados de nombres de organizaciones, dominios, direcciones IP o nombres de personas, efectuando una demo en directo de las dos primeras. Todas las consultas realizadas por las diversas herramientas son enviadas como mensaje mediante RabbitMQ desde unos workers a otros. A medida que van siendo obtenidos los datos de cada worker, estos son almacenados en la Base de Datos de neo4j.

La importancia de las relaciones entre los datos – Investigación a partir del nombre de la organización
La primera automatización parte de un listado de nombres de organizaciones introducidas por el usuario. En el momento de introducir dicho listado en la herramienta, enviará cada elemento de este a los workers correspondientes de RIPE y Libreborne (LibreBOR) para su consulta. De RIPE serán obtenidos los rangos IP, nombre por el que ha sido registrado y fechas de creación y modificación. En cuanto a Libreborne obtendrá información como NIF, situación mercantil, domicilio, provincia, empresas auditoras y todos los nombres de personas que tengan un cargo en la organización según publicaciones del BORME.
Los resultados obtenidos serán almacenados en neo4j mediante otro worker específico para ello. El worker de RIPE dispondrá de otra salida, una que ejecutará un worker en Shodan con el fin de consultar que rangos IP (recopilados mediante RIPE) están expuestos en Internet. Entre los datos que pueden ser detectados podemos tener direcciones IP, nombre organización, país, ASN, servicios y puertos expuestos, tecnologías y versiones utilizadas, CPE, CVE, ISP, entre otros. Cada resultado obtenido será almacenado en neo4j.

La importancia de las relaciones entre los datos – Investigación a partir del dominio
La segunda automatización parte en este caso de un listado de dominios introducidos por el usuario. En el momento de introducir dicho listado en la herramienta, enviará cada elemento de este a los workers correspondientes de las herramientas de VirusTotal y Hunter para su consulta. De VirusTotal serán obtenidos la dirección IP a la que apunta el propio dominio (la actual y un histórico de las últimas detectadas), subdominios o presencia de malware a través de URLs, hashes, etc. En cuanto a Hunter, obtendrá información como nombre completo de personas, correos electrónicos, perfiles de LinkedIn y/o Twitter, cargo y antigüedad profesional.
Los resultados obtenidos serán almacenados en neo4j mediante otro worker específico para ello. El worker de VirusTotal dispondrá de otra salida, una que ejecutará otro worker en VirusTotal centrado en analizar las direcciones IP detectadas. Uno de los puntos más importantes de este worker es la recopilación de todos los dominios que están apuntando en la actualidad a la dirección IP analizada, además de la detección de muestras de malware que hagan referencia a dicha IP. Por otra parte, el worker de Hunter dispone de otra salida, que ejecutará el worker de HaveIbeenPwned con el objetivo de comprobar si todos los correos electrónicos detectados en Hunter están presentes en algún Data Leak. El único dato recolectado será el nombre del Data Leak en cuestión, generando una relación con ello en neo4j.

En el momento de ejecutar las dos automatizaciones mencionadas, en neo4j serán generados los nodos con sus respectivos datos y las relaciones existentes entre los mismos. En la imagen inferior puede apreciarse la estructura generada.

Visualización del video del taller
Gracias a Yolanda Corral (@yocomu) de Palabra de Hacker (@Palabradehacker) tenéis disponible el video de este taller en su canal de YouTube. Os lo compartimos a continuación.
Visualización de la presentación del taller
La presentación del taller puede consultarse a continuación
[pdf-embedder url=»https://ginseg.com/wp-content/uploads/sites/2/2018/11/HoneyCon2018_Ciberinteligencia-IvanPortillo-GonzaloGonzalez.pdf»]
Conclusión
Como conclusión, tanto Gonzalo como yo tratamos de mostrar el potencial de integrar diferentes herramientas mediante un orquestador, relacionando los datos extraídos de cada uno de los resultados. En la investigación se demostró que partiendo de un único nombre de empresa y un dominio, podemos ser capaces de obtener la infraestructura y los datos que tiene expuestos una organizacón en Internet. Por medio de diferentes técnicas OSINT es posible recolectar los datos de diversas fuentes de manera automática, tratarlos y contextualizarlos, además de retroalimentar todos los datos en caso de ser necesario localizar más información.